
Chapter 3 – Definitions
3.1 Character
Generic term for a semantic symbol. Many possible interpretations exist in the context of encoding. In computing, the most important aspect is that characters can be letters, spaces or control characters which represent the end of a file or can be used to trigger a sound.
3.2 Glyph
One or more shapes that may be combined into a grapheme. In Latin, a glyph often has 2 variants like ‘A’ and ‘a’ and Arabic often has four. This term is context dependent and different styles or formats can be considered different glyphs. Most relevant in programming is that diacritic marks (e.g. accents like ‘ and ^) are also glyphs, which are sometimes represented with another at one point, like the à in ISO 8859-1 or as two separate glyphs, so an a and the combining ‘ (U+0300 and U+0061 combined as U+00E0).
3.3 Code point
A code point is an unsigned integer. The smallest code point is zero. Code points are usually written as hexadecimal, e.g. “0x20AC” (8,364 in decimal).
3.4 Character set (charset)
A character set, abbreviated charset, is a mapping between code points and characters. The mapping has a fixed size. For example, most 7 bits encodings have 128 entries, and most 8 bits encodings have 256 entries. The biggest charset is the Unicode Character Set 6.0 with 1,114,112 entries.
In some charsets, code points are not all contiguous. For example, the cp1252 charset maps code points from 0 though 255, but it has only 251 entries: 0x81, 0x8D, 0x8F, 0x90 and 0x9D code points are not assigned. Examples of the ASCII charset: the digit five (“5”, U+0035) is assigned to the code point 0x35 (53 in decimal), and the uppercase letter “A” (U+0041) to the code point 0x41 (65). The biggest code point depends on the size of the charset. For example, the biggest code point of the ASCII charset is 127 (27 − 1)
Charset examples:
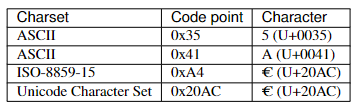
3.5 Character string
A character string, or “Unicode string”, is a string where each unit is a character. Depending on the implementation, each character can be any Unicode character, or only characters in the range U+0000—U+FFFF, range called the Basic Multilingual Plane (BMP). There are 3 different implementations of character strings:
- array of 32 bits unsigned integers (the UCS-4 encoding): full Unicode range
- array of 16 bits unsigned integers (UCS-2): BMP only
- array of 16 bits unsigned integers with surrogate pairs (UTF-16): full Unicode range
UCS-4 uses twice as much memory than UCS-2, but it supports all Unicode characters. UTF-16 is a compromise between UCS-2 and UCS-4: characters in the BMP range use one UTF-16 unit (16 bits), characters outside this range use two UTF-16 units (a surrogate pair, 32 bits). This advantage is also the main disadvantage of this kind of character string. The length of a character string implemented using UTF-16 is the number of UTF-16 units, and not the number of characters, which is confusing. For example, the U+10FFFF character is encoded as two UTF-16 units: {U+DBFF, U+DFFF}. If the character string only contains characters of the BMP range, the length is the number of charac- ters. Getting the nth character or the length in characters using UTF-16 has a complexity of ?(?), whereas it has a complexity of ?(1) for UCS-2 and UCS-4 strings. The Java language, the Qt library and Windows 2000 implement character strings with UTF-16. The C and Python languages use UTF-16 or UCS-4 depending on: the size of the wchar_t type (16 or 32 bits) for C, and the compilation mode (narrow or wide) for Python. Windows 95 uses UCS-2 strings.
See also:
UCS-2, UCS-4 and UTF-16 encodings, and surrogate pairs.







