


Chapter 1. Fundamental Concepts
This chapter is a short, casual introduction to Subversion and its approach to version control. We begin with a discussion of general version control concepts, work our way into the specific ideas behind Subversion, and show some simple examples of Subversion in use.
Even though the examples in this chapter show people sharing collections of program source code, keep in mind that Subversion can manage any sort of file collection—it’s not limited to helping computer programmers.
Version Control Basics
A version control system (or revision control system) is a system that tracks incremental versions (or revisions) of files and, in some cases, directories over time. Of course, merely tracking the various versions of a user’s (or group of users’) files and directories isn’t very interesting in itself. What makes a version control system useful is the fact that it allows you to explore the changes which resulted in each of those versions and facilitates the arbitrary recall of the same.
In this section, we’ll introduce some fairly high-level version control system components and concepts. We’ll limit our discussion to modern version control systems—in today’s interconnected world, there is very little point in acknowledging version control systems which cannot operate across wide-area networks.
The Repository
At the core of the version control system is a repository, which is the central store of that system’s data. The repository usually stores information in the form of a filesystem tree—a hierarchy of files and directories. Any number of clients connect to the repository, and then read or write to these files. By writing data, a client makes the information available to others; by reading data, the client receives information from others. Figure 1.1, “A typical client/server system” illustrates this.
Figure 1.1. A typical client/server system
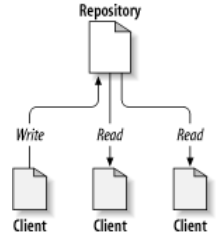
Why is this interesting? So far, this sounds like the definition of a typical file server. And indeed, the repository is a kind of file server, but it’s not your usual breed. What makes the repository special is that as the files in the repository are changed, the repository remembers each version of those files.
When a client reads data from the repository, it normally sees only the latest version of the filesystem tree. But what makes a version control client interesting is that it also has the ability to request previous states of the filesystem from the repository. A version control client can ask historical questions such as “What did this directory contain last Wednesday?” and “Who was the last person to change this file, and what changes did he make?” These are the sorts of questions that are at the heart of any version control system.
The Working Copy
A version control system’s value comes from the fact that it tracks versions of files and directories, but the rest of the software universe doesn’t operate on “versions of files and directories”. Most software programs understand how to operate only on a single version of a specific type of file. So how does a version control user interact with an abstract—and, often, remote—repository full of multiple versions of various files in a concrete fashion? How does his or her word processing software, presentation software, source code editor, web design software, or some other program—all of which trade in the currency of simple data files—get access to such files? The answer is found in the version control construct known as a working copy.
A working copy is, quite literally, a local copy of a particular version of a user’s VCS-managed data upon which that user is free to work. Working copies1 appear to other software just as any other local directory full of files, so those programs don’t have to be “version-control-aware” in order to read from and write to that data. The task of managing the working copy and communicating changes made to its contents to and from the repository falls squarely to the version control system’s client software.
Versioning Models
If the primary mission of a version control system is to track the various versions of digital information over time, a very close secondary mission in any modern version control system is to enable collaborative editing and sharing of that data. But different systems use different strategies to achieve this. It’s important to understand these different strategies, for a couple of reasons. First, it will help you compare and contrast existing version control systems, in case you encounter other systems similar to Subversion. Beyond that, it will also help you make more effective use of Subversion, since Subversion itself supports a couple of different ways of working.
The problem of file sharing
All version control systems have to solve the same fundamental problem: how will the system allow users to share information, but prevent them from accidentally stepping on each other’s feet? It’s all too easy for users to accidentally overwrite each other’s changes in the repository.
Consider the scenario shown in Figure 1.2, “The problem to avoid”. Suppose we have two coworkers, Harry and Sally. They each decide to edit the same repository file at the same time. If Harry saves his changes to the repository first, it’s possible that (a few moments later) Sally could accidentally overwrite them with her own new version of the file. While Harry’s version of the file won’t be lost forever (because the system remembers every change), any changes Harry made won’t be present in Sally’s newer version of the file, because she never saw Harry’s changes to begin with. Harry’s work is still effectively lost—or at least missing from the latest version of the file—and probably by accident. This is definitely a situation we want to avoid!






